运行以下命令以将此阶段文件与 rpicam-hello 一起使用: rpicam-hello --lores-width 128 --lores-height 96 --post-process-file motion_detect.json
使用 OpenCV 进行后处理注意:这些阶段需要安装 OpenCV。您可能需要使用 OpenCV 支持重新构建 rpicam-apps。 sobel_cv阶段此阶段将 Sobel 滤镜应用于图像以强调边缘。
您可以使用以下参数配置此阶段: 默认sobel_cv.json文件: {
"sobel_cv" : {
"ksize": 5
}
}
例:

使用 Sobel 滤镜来强调边缘。 face_detect_cv阶段此阶段使用 OpenCV Haar 分类器来检测图像中的人脸。它在键 face_detect.results 下返回人脸位置元数据,并选择性地在图像上绘制位置。
您可以使用以下参数配置此阶段: cascade_name | 可以找到 Haar 级联的文件的名称 |
|---|
scaling_factor | 确定在图像中搜索人脸的比例范围 | min_neighbors | 需要的最小重叠邻居数才能算作一个人面 | min_size | 最小脸部尺寸 | max_size | 最大脸部尺寸 | refresh_rate | 在尝试重新运行人脸检测器之前要等待多少帧 | draw_features | 是否在返回的图像上绘制人脸位置 |
face_detect_cv阶段仅在预览和视频捕获期间运行。它忽略了静止图像捕获。它在分辨率介于 320×240 和 640×480 像素之间的低分辨率流上运行。
默认face_detect_cv.json文件: {
"face_detect_cv" : {
"cascade_name" : "/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt.xml",
"scaling_factor" : 1.1,
"min_neighbors" : 2,
"min_size" : 32,
"max_size" : 256,
"refresh_rate" : 1,
"draw_features" : 1
}
}
例:
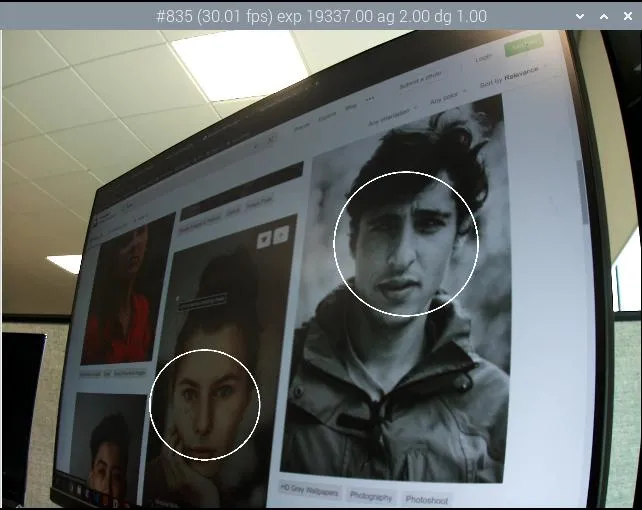
将检测到的人脸绘制到图像上。 annotate_cv阶段此阶段使用与信息文本选项相同的替换百分比将文本写入图像的顶角。
首先解释 info-text 指令,然后将任何剩余的标记传递给 strftime。
例如,若要在视频上实现日期时间戳,请传递 %F %T %z: %F显示 ISO-8601 日期 (2023-03-07) %T显示 24 小时当地时间(例如“09:57:12”) %z显示相对于 UTC 的时区(例如“-0800”)
此阶段不输出任何元数据,但它会写入在 annotate.text 中找到的元数据,以代替 JSON 配置文件中的任何内容。这允许其他后期处理阶段将文本写入图像。
您可以使用以下参数配置此阶段: text | 要写入的文本字符串 |
|---|
fg | 前景色 | bg | 背景颜色 | scale | 与文本大小成正比的数字 | thickness | 确定文本粗细的数字 | alpha | 覆盖背景像素时要应用的 alpha 量 |
默认annotate_cv.json文件: {
"annotate_cv" : {
"text" : "Frame %frame exp %exp ag %ag dg %dg",
"fg" : 255,
"bg" : 0,
"scale" : 1.0,
"thickness" : 2,
"alpha" : 0.3
}
}
示例:

Writing camera and date information onto an image with annotations. 使用 TensorFlow Lite 进行后处理先决条件这些阶段需要导出 C++ API 的 TensorFlow Lite (TFLite) 库。TFLite 不会以这种形式分发库,但您可以下载并安装从 lindevs.com 导出 API 的版本。
安装后,您必须使用 TensorFlow Lite 支持重新编译 rpicam-apps。
object_classify_tf阶段 object_classify_tf阶段下载: https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_2018_08_02/mobilenet_v1_1.0_224_quant.tgz
object_classify_tf 使用 Google MobileNet v1 模型对相机图像中的对象进行分类。此阶段需要labels.txt文件。
您可以使用以下参数配置此阶段: top_n_results | 要显示的结果数 |
|---|
refresh_rate | 模型运行之间必须经过的帧数 | threshold_high | 置信度阈值(介于 0 和 1 之间),其中对象被视为存在 | threshold_low | 置信度阈值:对象在作为匹配项丢弃之前必须低于该阈值 | model_file | TFLite 模型文件的文件路径 | labels_file | 包含对象标签的文件的文件路径 | display_labels | 是否在图像上显示对象标签;插入要呈现的 annotate_cv 阶段的 Annotate.text 元数据 | verbose | 将更多信息输出到控制台 |
文件示例object_classify_tf.json: {
"object_classify_tf" : {
"top_n_results" : 2,
"refresh_rate" : 30,
"threshold_high" : 0.6,
"threshold_low" : 0.4,
"model_file" : "/home//models/mobilenet_v1_1.0_224_quant.tflite",
"labels_file" : "/home//models/labels.txt",
"display_labels" : 1
},
"annotate_cv" : {
"text" : "",
"fg" : 255,
"bg" : 0,
"scale" : 1.0,
"thickness" : 2,
"alpha" : 0.3
}
}
载物台在大小为 224×224 的低分辨率流图像上运行。运行以下命令以将此阶段文件与 rpicam-hello 一起使用: rpicam-hello --post-process-file object_classify_tf.json --lores-width 224 --lores-height 224
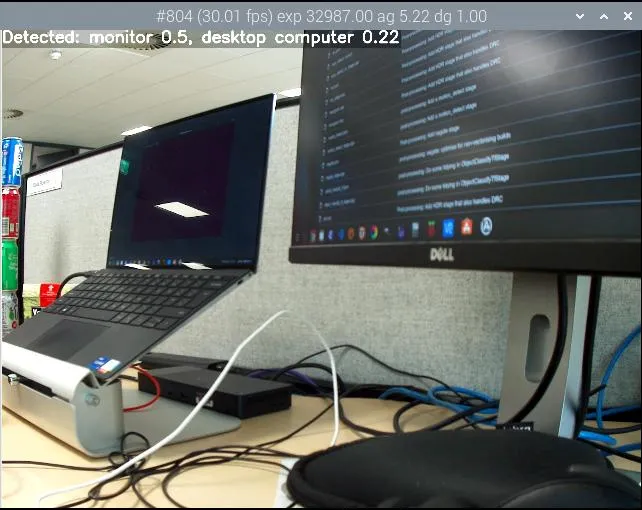
台式计算机和显示器的对象分类。
pose_estimation_tf阶段下载: https://github.com/Qengineering/TensorFlow_Lite_Pose_RPi_32-bits
pose_estimation_tf使用 Google MobileNet v1 模型来检测姿势信息。
您可以使用以下参数配置此阶段: refresh_rate | 模型运行之间必须经过的帧数 |
|---|
model_file | TFLite 模型文件的文件路径 | verbose | 将额外信息输出到控制台 |
使用单独的plot_pose_cv舞台将检测到的姿势绘制到主图像上。
您可以使用以下参数配置plot_pose_cv阶段: confidence_threshold | 确定要抽取多少的置信度阈值;可以小于零 |
|---|
|
文件pose_estimation_tf.json示例: {
"pose_estimation_tf" : {
"refresh_rate" : 5,
"model_file" : "posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite"
},
"plot_pose_cv" : {
"confidence_threshold" : -0.5
}
}
载物台在大小为 257×257 的低分辨率流图像上运行。由于 YUV420 图像的尺寸必须为偶数,因此 YUV420 图像的四舍五入为 258×258。
运行以下命令以将此阶段文件与 rpicam-hello 一起使用: rpicam-hello --post-process-file pose_estimation_tf.json --lores-width 258 --lores-height 258

成年人类男性的姿势估计。
object_detect_tf阶段下载: https://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
object_detect_tf使用 Google MobileNet v1 SSD(单次检测器)模型来检测和标记对象。
您可以使用以下参数配置此阶段: refresh_rate | 模型运行之间必须经过的帧数 |
|---|
model_file | TFLite 模型文件的文件路径 | labels_file | 包含标签列表的文件的文件路径 | confidence_threshold | 接受匹配前的置信度阈值 | overlap_threshold | 确定要合并为单个匹配项的匹配项之间的重叠量。 | verbose | 将额外信息输出到控制台 |
使用单独的object_detect_draw_cv舞台将检测到的对象绘制到主图像上。
您可以使用以下参数配置object_detect_draw_cv阶段: line_thickness | 边界框线的粗细 |
|---|
font_size | 用于标签的字体大小 |
文件object_detect_tf.json示例: {
"object_detect_tf" : {
"number_of_threads" : 2,
"refresh_rate" : 10,
"confidence_threshold" : 0.5,
"overlap_threshold" : 0.5,
"model_file" : "/home//models/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29/detect.tflite",
"labels_file" : "/home//models/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29/labelmap.txt",
"verbose" : 1
},
"object_detect_draw_cv" : {
"line_thickness" : 2
}
}
| 
